滝沢研博士1年のLiuです。HOT CHIPS 33に参加しました。
HOT CHIPSは、高性能マイクロプロセッサと集積回路に関する半導体業界の主要な国際学会の一つです。今年は、有名企業や国立研究所の技術者やチップ設計者が最新の技術や製品を紹介・発表しました。今回の学会は、8月22日から24日までの3日間、オンラインで開催されました。
CPU、データプロセッサ、機械学習プラットフォームなどのセッションがあり、質の高いプレゼンテーションが数多くあり、多くのイノベーションや新技術が紹介されていました。
今年は、トップレベルの企業が新しいCPUを発表しました。この場をかりて、興味を持ったいくつかのトピックスとその感想を紹介します。
1. Intel Alder Lake
Alder Lakeは、Intel Coreプロセッサの最新世代です。コアの設計がこれまでとは全く異なります。PコアとEコアというアーキテクチャの異なる2つのコアを使い、ハイブリッドな性能を実現しています。


図1 PコアとEコア (出所: Intel)
Pコアはシングルおよび軽量スレッドのスケーラブルなアプリケーションで高い性能を発揮し、Eコアはマルチスレッドのアプリケーションで優れたスループットを発揮します。スケジューリングについては、IntelはThread Directorを使用して、適切なワークロードを適切なタイミングで適切なコアに配置します。PコアとEコアのサイクルあたりの命令実行数 (IPC) の違いに基づいて、アプリケーションは4つのクラスに分類されます。エネルギー効率や性能に関する情報は、定期的にEHFIテーブルに書き込まれ、OSのスケジューラが最適なコアの割り当てを選択します。Thread Directのアーキテクチャを以下に示します。
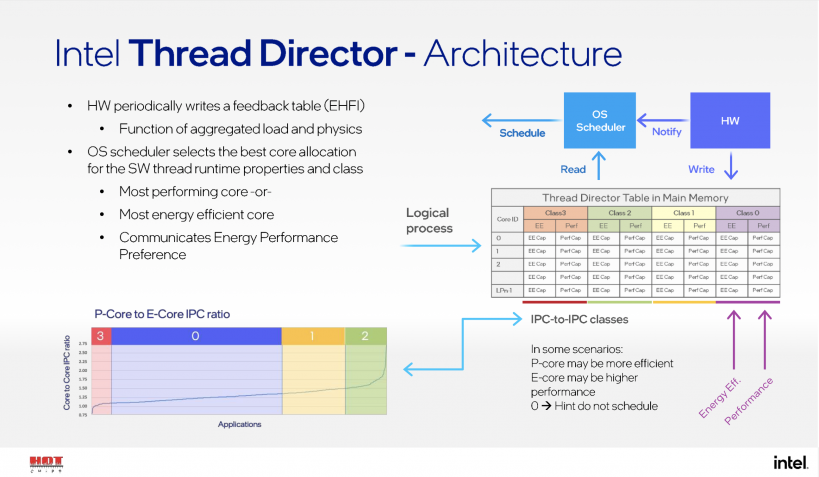
図2 Thread Director (出所: Intel)
2. AMD Zen3
Zen2と比較して、新世代は19%のIPC向上を達成しています。非常に大きい技術進歩です。図は、Zen3の主な変更点を示しています。
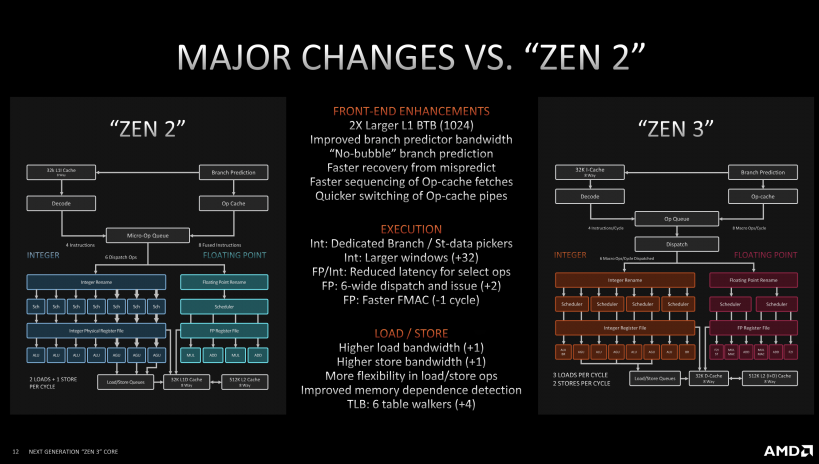
図3 Zen3コアとZen2コアを比較 (出所: AMD)
私にとって最も興味深いのは、Zen3のキャッシュ階層です。L3の総サイズは変わりませんが、コアごとの直接アクセスが2倍になり、実効メモリのレイテンシが減少しています。また、L2とL3のミスの少なさにも驚かされます。 また、3D V-cache技術により、L3は192MBと驚異的な容量となっています。


図4 Zen3のキャッシュ階層と3D V-cache技術 (出所: AMD)
3. IBM Telum
新しいIBM Zシステムは、Z15とはかなり異なっており、特にキャッシュ階層が異なっています。各コアには32MBのプライベートL2キャッシュがあり、これはZ15のL2キャッシュの8倍にあたります。しかしTelumでは、物理的なL3およびL4キャッシュは存在せず、IBMはL2を使用して仮想的なL3およびL4キャッシュを生成します。これにより、L3とL4の機能はそのままに、チップ面積とレイテンシーを大幅に削減し、コアあたりのキャッシュサイズをさらに向上させています。このような実装により、1ソケットあたり40%以上の性能向上を実現しています。

図5 IBM Telumのキャッシュ階層 (出所: IBM)
4. Intel Xeon Sapphire Rapids
近年、プロセッサーの設計では、モジュラー・アーキテクチャーが普及しています。これは、ダイサイズが小さければ小さいほど、チップ製造における歩留まりが良くなるためです。Sapphire Rapidsでは、EMIB技術を用いてマルチタイルデザインを実現しています。各タイルに搭載されているアクセラレーション・エンジンは重要な部品のひとつです。データストリーミング、クイックアシスト技術、ダイナミックロードバランサーなどを搭載し、コモンモードタスクのオフロードをサポートしています。

図6 Sapphire Rapids (出所: Intel)
また、今回は共有LLCも増え、2つのモード (フラット、キャッシング) を持つHBMについても言及されています。
まだまだ、全てを紹介しきれないほどの素晴らしい発表がありました。例えば、SamsungのHBM2-PIM、チップレットと3Dパッケージング、などなどですね。今回の学会では、多くの刺激的なアイデアや技術を学ぶことができました。私は、創造性と改善を達成するための努力に感銘を受けました。これらの新しいアーキテクチャやアイデアは、チップ設計分野における人気のあるトレンドを示しており、私自身の研究にも大いに役立つと思います。