Our members’ paper was selected for the best paper award at AutoML2018!
Title:Automatic Hyperparameter Tuning of Machine Learning Models under Time Constraints
Authors: Zhen Wang, Agung Mulya, Ryusuke Egawa, Reiji Suda, Hiroyuki Takizawa


Booth Exhibition @ SC18 Dallas
Our group exhibited our research activities at SC 18 with IFS(Institute of Fluid Science) and IMR (Institute of Material Research)!Thank you for visiting our Booth.

Poster presentation @ SC18
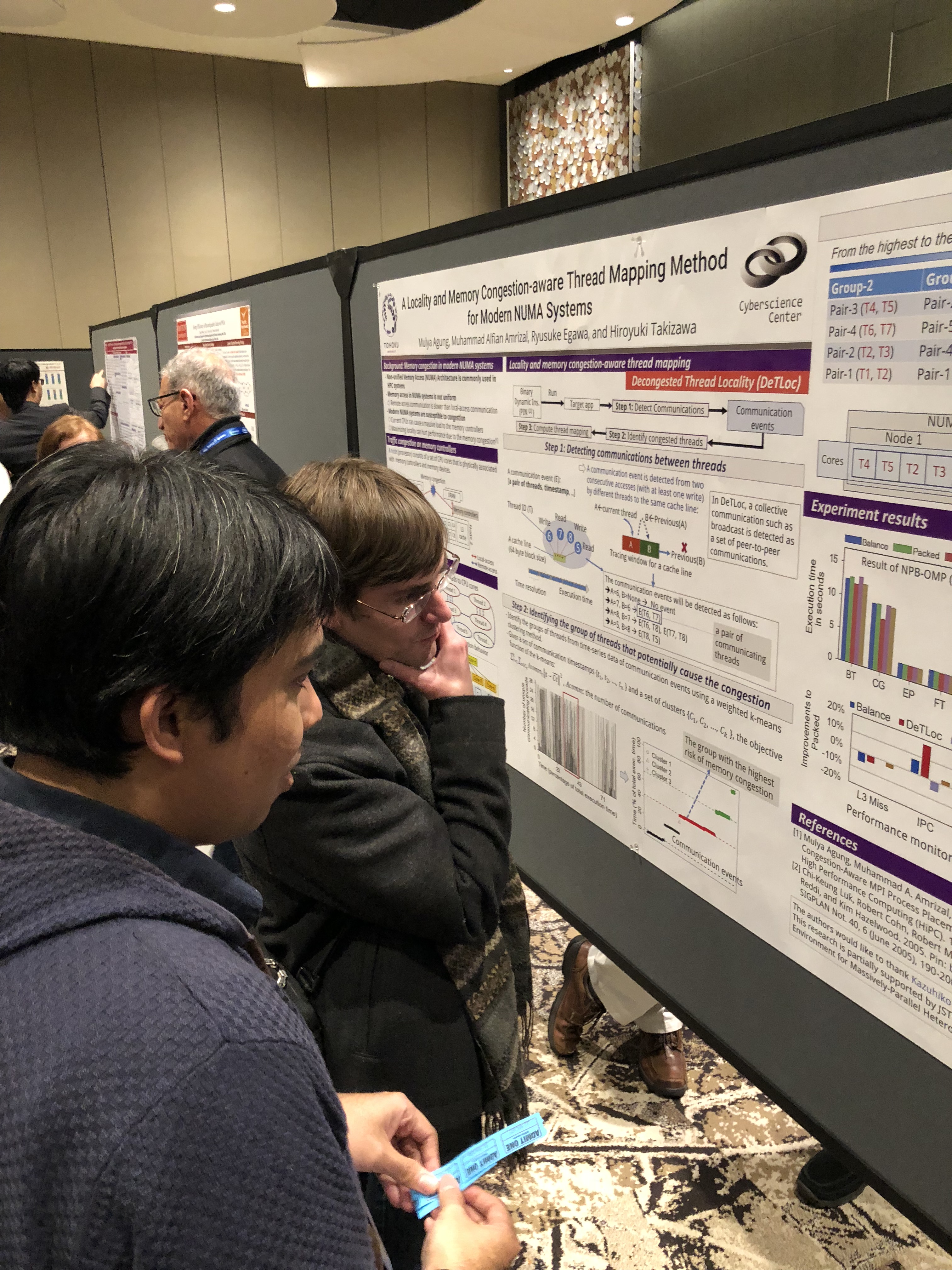
M. Agung (D3) presented his research effort at SC18!
M. Agung, M. A. Amrizal, R. Egawa, and H. Takizawa, “A Locality and Memory Congestion-aware Thread Mapping Method for Modern NUMA Systems,” Poster Presentation at SC18, 13 Nov. 2018, Dallas.
Dr. Keita Teranishi will visit our lab on Nov 22!
Dr. Keita Teranishi will visit our lab and give a talk on Nov 22.
He is a principal member of technical staff at Sandia National Laboratories, California, USA. He received the BS and MS degrees from the University of Tennessee, Knoxville, in 1998 and 2000, respectively, and the PhD degree from The Pennsylvania State University, in 2004. His research interests are parallel programming model, fault tolerance, numerical algorithm and data analytics for high performance computing systems.
The abstract of his talk is as follows.
Abstract: Tensors have found utility in a wide range of applications, such as chemometrics, network traffic analysis, neuroscience, and signal processing. Many of these data science applications have increasingly large amounts of data to process and require high-performance methods to provide a reasonable turnaround time for analysts. Sparse tensor decomposition is a tool that allows analysts to explore a compact representation (low-rank models) of high-dimensional data sets, expose patterns that may not be apparent in the raw data, and extract useful information from the large amount of initial data. In this work, we consider decomposition of sparse count data using CANDECOMP-PARAFAC Alternating Poisson Regression (CP-APR).
Unlike the Alternating Least Square (ALS) version, CP-APR algorithm involves non-trivial constraint optimization of nonlinear and nonconvex function, which contributes to the slow adaptation to high performance computing (HPC) systems. The recent studies by Kolda et al. suggest multiple variants of CP-APR algorithms amenable to data and task parallelism together, but their parallel implementation involves several challenges due to the continuing trend toward a wide variety HPC system architecture and its programming models.
To this end, we have implemented a production-quality sparse tensor decomposition code, named SparTen, in C++ using Kokkos as a hardware abstraction layer. By using Kokkos, we have been able to develop a single code base and achieve good performance on each architecture. Additionally, SparTen is templated on several data types that allow for the use of mixed precision to allow the user to tune performance and accuracy for specific applications. In this presentation, we will use SparTen as a case study to document the performance gains, performance/accuracy tradeoffs of mixed precision in this application, development effort, and discuss the level of performance portability achieved. Performance profiling results from each of these architectures will be shared to highlight difficulties of efficiently processing sparse, unstructured data. By combining these results with an analysis of each hardware architecture, we will discuss some insights for improved use of the available cache hierarchy, potential costs/benefits of analyzing the underlying sparsity pattern of the input data as a preprocessing step, critical aspects of these hardware architectures that allow for improved performance in sparse tensor applications, and where remaining performance may still have been left on the table due to having single algorithm implementations on diverging hardware architectures.
M1 student Shiotsuki presented at SWoPP2018
M1 student Shiotsuki made presentations at SWoPP2018 (Summer United Workshops on Parallel, Distributed and Cooperative Processing) held at 熊本市国際交流会館 from July 30th to August 1st.
SWoPP2018:
https://sites.google.com/site/swoppweb/swopp2018
He made a presentation on “Performance evaluation of inter-process communication of SX-Aurora TSUBASA”.

Presentation at SX-Aurora TSUBASA Forum
I gave a talk at SX-Aurora TSUBASA Forum taken place at the NEC headquarter.
My talk was about a hot topic, the performance and functionality of NEC’s new product, SX-Aurora TSUBASA.
I am glad the audiences enjoyed it.
https://jpn.nec.com/event/180727aurora/index.html (in Japanese)

Presentation at iWAPT2018
I attended IPDPS 2018 in Vancouver, and gave a talk at the international workshop on automatic performance tuning, iWAPT 2018, on behalf of Yuki Kawarabatake who was the first author of the work. During the stay, I also visited Stanley Park, a great park full of nature. It’s a pity I am not good at taking a selfie… 🙁
Hiro



NUG30@Aachen
I have presented our joint research effort at NUG30@Aachen Germany. I stayed as a visiting researcher at RWTH GRS in Aachen from Aug. to Oct. 2011, but it was my first visit in about seven years. The townscape was unchanged from that time, and I felt relieved somehow :-).
Ryusuke



Laboratory name is changed to “High-Performance Computing”
From April 1, 2018, our laboratory will be renamed “Ultra High Speed Information Processing” to “High Performance Computing”.
We will continue to work on research on high performance computing systems and their applications, and also system software that supports high performance computing systems.
Professor Takizawa and Associate Professor Egawa presented their research results at the 27th WSSP
Professor Takizawa and Associate Professor Egawa made presentations at Workshop on Sustained Simulation Performance (WSSP) held at the Cyberscience Center on March 22 and 23.
27th WSSP (https://www.sc.cc.tohoku.ac.jp/wssp27/ja/index.html)
This workshop was hosted by Tohoku University Cyberscience Center, Japan Ocean Research and Development Organization (JAMSTEC), Stuttgart University High Performance Calculation Center (HLRS) in Germany, and NEC, and JHPCN.This workshop invited researchers and supercomputer designers who are internationally active in computational science.We will exchange information on the latest research results on high performance and high efficiency large scale scientific computation, and discuss on future research and development of supercomputer. From our laboratory Professor Takizawa announced the result of code optimization using machine learning, Associate Prof. Egawa on the high energy efficiency job scheduling for the HPC system based on the execution time prediction of the job. (These outcomes summarize the results of Teng and Kawaharaba who completed master’s degree this year and finished.)
Hiroyuki Takizawa, “Towards prediction of effective optimizations in performance engineering.”
Ryusuke Egawa, “Job Run-time Estimation toward Energy-aware System Operation.”