Creating future supercomputing technologies and their innovative applications
Our laboratory focuses its research on creating next-generation supercomputing technologies that are practical and indispensable for advancing the state-of-the-art science and technology, and also for supporting innovations in engineering, while often considering practical issues at operation of Supercomputer AOBA. Particularly, our research focus is on developing system software technologies to fully exploit the system performance, and also on exploring new applications of using supercomputers. For example, we are lately exploring effective ways of (partially) replacing expert programmers’ work with machine learning technologies, and also of effective use of a supercomputer for urgent computing. Besides, we explore the ways of making the best use of emerging hardware components, such as modern vector processors, quantum annealers, and reconfigurable hardware devices in the field of supercomputing.

Use of a supercomputer as the core of a cyber-physical system
Thanks to advances in sensor technology and IoT devices, a huge amount of data are being produced moment by moment. For realizing flexible operation of a supercomputer adapting to realtime proessing of observation data, we develop system software technologies to enable a supercomputer usually in academic use to be used certainly for disaster prevention and mitigation at emergency.
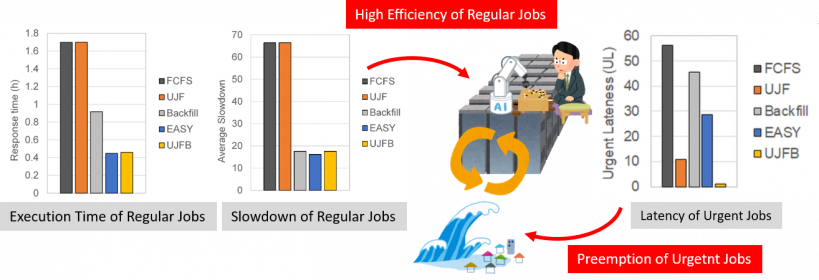
- Mulya Agung, Yuta Watanabe, Henning Weber, Ryusuke Egawa, and Hiroyuki Takizawa, “Preemptive Parallel Job Scheduling for Heterogeneous Systems Supporting Urgent Computing,” IEEE Access, Volume 9, pp. 17557-17571, 2021.(DOI)
- Minglu Zhao, Reo Furuhata, Mulya Agung, Hiroyuki Takizawa, and Tomoya Soma, “Failure Prediction in Datacenters Using Unsupervised Multimodal Anomaly Detection,” The IEEE BigData 2020, the third international conference on the Internet of Things Data Analytics (IoTDA), 2020.(DOI)
Supercomputer programming aided by machine learning technologies
Machine learning technologies are now emerging very quickly. It might be difficult even for the latest machine learning technologies to fully automate performance-aware, supercomputer programming that has been achieved only by human experts with deeply considering individual system configurations. However, we believe the programming process could partially be automated by machine learning. Therefore, we are exploiting effective ways of using machine learning for performance-aware programming.
- Hang Cui, Shoichi Hirasawa, Hiroaki Kobayashi, and Hiroyuki Takizawa, “A Machine Learning-based Approach for Selecting SpMV Kernels and Matrix Storage Formats,” IEICE Transactions on Information and Systems, Vol.E101-D, No.9, Sep 2018 (DOI)
- Zhen Wang, Agung Mulya, Ryusuke Egawa, Reiji Suda, and Hiroyuki Takizawa, “Automatic Hyperparameter Tuning of Machine Learning Models under Time Constraints,” IEEE BigData 2018 workshop, The Second International Workshop on Automation in Machine Learning and Big Data (AutoML 2018), December 13, 2018, Seattle, WA, USA.(DOI)
- Reo Furuhata, Minglu Zhao, Mulya Agung, Ryusuke Egawa, and Hiroyuki Takizawa, “Improving the accuracy in SpMV implementation selection with machine learning,” The Eighth International Conference on Computing and Networking Workshops (CANDARW), 2020.(DOI)
Programming environments for assigning right tasks to right processors
For a given task, general-purpose processors would be less efficient than special-purpose processors designed for the task. Thus, modern supercomputers are equipped with several kinds of processors, each of which has it own pros and cons. We are developing programming environments for proper use of various processors, such as vector processors, GPUs, quantum annealers, and FPGAs.
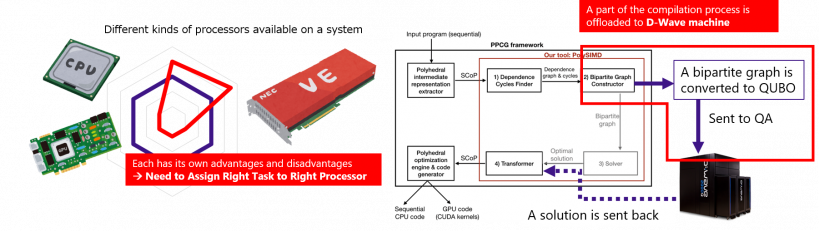
- Yinan Ke, Mulya Agung, and Hiroyuki Takizawa, “neoSYCL: a SYCL implementation for SX-Aurora TSUBASA,” International Conference on High Performance Computing in Asia-Pacific Region, pp.50-57, 2021. (DOI)
- Yuta Sasaki, Michael Ryan Zielewski, Mulya Agung, Ryusuke Egawa and Hiroyuki Takizawa, “Quantum Compiler : Automatic Vectorization Assisted by Quantum Annealer,” The ISC High Performance conference 2020 (poster), 2020.(link)
- Michael Ryan Zielewski, Mulya Agung, Ryusuke Egawa and Hiroyuki Takizawa, “Improving Quantum Annealing Performance on Embedded Problems,” Supercomputing Frontiers and Innovations, Volume 7, Number 4, pp. 32-48, 2020.(DOI)
Fully exploiting a supercomputer to the limit!
Various computers are used everywhere in our daily lives, and one might consider the computing power is high enough. In reality, however, the performance of even the latest computer is far from enough in not a few fields. Nowadays, numerical simulations using large-scale high-performance computing systems, so-called supercomputers, are imperative in fields of science and technology, and hence new supercomputers are being intensively developed all over the world. To further increase the performance, future supercomputers will be much larger and much more complex than any of current supercomputers. An important technical issue is how to exploit the potential of such a future supercomputer as effectively as possible.
To solve the issue, we have been extensively studying high-performance computing technologies from system design to programming and utilization technologies. Especially, we have been leading an international joint research project for reducing the programming efforts required to exploit the performance of a supercomputer, resulting in some pioneering work. Visit the following project page for more details.
(Xevolver Project Page) https://xev.sc.cc.tohoku.ac.jp
Moreover, we have joint-research projects with researchers in different areas to develop practical applications that can fully exploit the potential of a supercomputer, and thereby create application optimization and system software technologies. By fully exploiting a supercomputer and knowing the limitations, we also discuss the system design and mandatory features of future supercomputers, and develop their component technologies.
- Kazuhiko Komatsu, Ayumu Gomi, Ryusuke Egawa, Daisuke Takahashi, Reiji Suda, and Hiroyuki Takizawa, “Xevolver: A code transformation framework for separation of system-awareness from application codes,” Concurrency Computation, Vol. 32, No. 7, 2020.(DOI)
- Ryusuke Egawa, Souya Fujimoto, Tsuyoshi Yamashita, Daisuke Sasaki, Yoko Isobe, Yoichi Shimomura, and Hiroyuki Takizawa, “Exploiting the Potentials of the Second Generation SX-Aurora TSUBASA,” The 11th International Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS’20), Nov. 2020. (DOI)
- Yuta Sasaki, Ayumu Ishizuka, Mulya Agung and Hiroyuki Takizawa, “Evaluating I/O Acceleration Mechanisms of SX-Aurora TSUBASA,” 2021 IEEE International Parallel & Distributed Processing Symposium Workshops, 2021.(DOI)
Thesis/Dissertation theme
FY2025
Master Thesis
- Application of Explainable AI in Software Automatic Tuning
- Semantic Equivalence Verification of HPC Codes Using LLMs
- Meta-scheduling of workflow tasks in a distributed computing
- Phase-Aware Scheduling for Temporally Varying I/O Demands
Undergraduate thesis
- Combining lossy compression with multi-level caching for interactive data analysis over networks
FY2024
Master Thesis
- Development of a Real-Time 3D X-ray Ptychography Workflow Using Surrogate Models
- Understanding Workload Interference and Its Impact on Vector Supercomputer Performance
Undergraduate thesis
- Research on Code Optimization Support using Large Language Models
- Research on Cache Management Techniques in RISC-V Vector Extensions
FY2023
Doctoral Dissertation
- Enhancing Quantum Annealing Performance through Thermalization
- Contention-aware Control Mechanisms for Shared Caches on Multiprocessors
Master Thesis
- Combining lossy compression with multi-level caching for interactive data analysis over networks
- A power management method for high performance computing systems based on energy consumption allocation
- A job scheduling method considering on-demand job execution and power
FY2022
Master Thesis
- Parallel Task Scheduling for FPGA Clusters
- Improving the efficiency of Parallel Bayesian Optimization
- Task-based runtime for multi-node vector systems
- Equivalence Checking for User-Defined Code Transformation
FY2021
Master Thesis
- Compiler Optimizations Based on a Data-Driven Approach
- Spatiotemporal Anomaly Detection in Large-Scale Time-Series Data
- Efficient Parameter Search Based on Prior Knowledge and its Application
- Improving Computational Efficiency of Heterogeneous Computing Systems by Predicting Conflicts among Concurrently Running Tasks
- A Device Selection Mechanism for Offload Programming
- Memory-aware Task Mapping for Heterogeneous Multi-Core Systems
- Machine Learning-based Compile Option Selection
FY2020
Master Thesis
- Improving Quantum Annealer Performance on Large Ising Models
- Memory Access Optimization with Polymorphic Data Layout
- A Conflict-Aware Capacity Control Mechanism for Deep Cache Hierarchy
- An Offloading Framework for Single-Source C++ Programming
FY2019
Doctoral Dissertation
- Task Mapping for Coordinating Locality and Memory Congestion on NUMA System
- Interconnection Networks for High-Performance Stream Computing with FPGA Clusters
Master Thesis
- Meta-Programming for Heterogeneous Computing Systems
- Use of FPGAs for efficient communication among Vector Processors
- Acceleration of Hyper-Parameter Auto-Tuning with Parallelization and Time Constraints
- Task Mapping Strategies for Task-based Parallel Execution
FY2018
Doctoral Dissertation
- OpenMP Extensions for Irregular Parallel Applications
Master Thesis
- Design and Evaluation of Stream-Computing Machines for N-Body Problems
FY2017
Master Thesis
- Program Performance Optimization Using Machine Learning Models
- Power-aware Job Scheduling for High Performance Computing Systems
- Thermal-aware Checkpoint Interval Tuning for High Performance Computing
- Automatic Hyperparameter Tuning of Machine Learning Models